Multi-AZ RDS failover 테스트 검증기 (feat.AWS FIS)
Multi-AZ RDS failover 테스트 검증기 (feat.AWS FIS)
AWS FIS로 운영 DB에 강제 failover를 일으켜, "Multi-AZ가 정말 장애를 견디는가"를 숫자로 확인한 기록. 결론부터: DB는 15초 만에 살아났는데, 앱은 15분 동안 못 붙었다.
들어가며
RDS를 Multi-AZ로 켜두면 한 가용영역(AZ)이 죽어도 다른 AZ가 받아준다고 한다. 콘솔에서 체크박스 하나 켜는 걸로 "장애 대응 완료"라고 믿기 쉽다. 그런데 정말 그런가? 켜 두는 것과 실제로 견디는 것은 다른 이야기다.
그래서 직접 깨뜨려보기로 했다. AWS FIS(Fault Injection Simulator)로 운영 중인 RDS Primary를 강제로 재부팅시켜 failover를 일으키고, 그 과정을 Grafana로 초 단위로 관측했다. 두 번에 걸쳐 진행했는데, 1차에서 예상 못 한 게 터졌고 2차에서 그 원인을 끝까지 파고들었다.
이 글의 한 문장 요약은 이거다 — DB 가용성과 서비스 가용성은 같은 숫자가 아니다.
0. 먼저 개념부터
본문에 계속 나오는 용어 다섯 개만 잡고 가자.
- FIS (Fault Injection Simulator) — AWS의 장애 주입 도구. "이 자원에 이런 장애를 일으켜라"를 템플릿으로 정의해 일부러 장애를 내고 시스템 반응을 관측한다. 카오스 엔지니어링의 실행 도구다.
- Multi-AZ Failover — RDS를 두 AZ에 Primary·Standby로 이중화한 구성. Primary가 죽으면 다른 AZ의 Standby가 새 Primary로 승격된다. 평소 동기 복제라 데이터 손실이 없다.
- RTO (Recovery Time Objective) — 장애부터 복구까지 허용하는 목표 시간. 어느 계층을 기준으로 재느냐(DB냐 앱이냐)에 따라 값이 완전히 달라진다 — 이 글의 핵심.
- HikariCP (커넥션 풀) — Spring Boot 기본 DB 커넥션 풀. 요청마다 연결을 새로 만들지 않고 미리 만든 연결을 재사용한다. failover로 Primary가 바뀌면 풀에 있던 연결은 옛 Primary를 바라보는 죽은 연결이 된다. 이걸 얼마나 빨리 버리고 새로 만드냐가 앱 복구 속도를 가른다.
- warm pool — 방금 새 연결로 통째로 갈려서 전부 "신선한" 상태의 풀. 반대는 오래 묵은 연결로 찬 cold pool. (뒤에서 함정으로 다시 등장한다.)
1. 무엇을 테스트했나
| 구성 | 내용 |
|---|---|
| 대상 DB | prod-rds · PostgreSQL 18.3 · db.t3.small · Multi-AZ = true |
| 앱 계층 | ECS · Spring Boot · HikariCP |
| 트래픽 | ALB → Target Group → ECS |
| 안전장치 | Stop Condition = CloudWatch 5xx 알람 |
| 관측 | Grafana(AMG) + RDS Recent events |
합격 기준은 세 가지로 잡았다.
- DB RTO < 120초 — DB가 다시 쓰기 가능해지기까지
- 서비스 자동 복구 — 사람 손 안 대고 앱이 정상으로 돌아오는가
- 데이터 무손실 — failover 중 쓰기 데이터가 사라지지 않는가
failover가 일어나는 방식은 이렇다.

Primary(2c)가 재부팅되면 Standby(2a)가 새 Primary로 승격된다. 문제는 오른쪽 — DB는 2a로 옮겨갔는데 앱의 커넥션 풀은 여전히 옛 Primary(2c)를 붙들고 있다.
2. 1차: 일단은 평온했다, 5xx가 터지기 전까진
FIS 액션 aws:rds:reboot-db-instances에 forceFailover=true를 줘서 Primary를 강제로 재부팅했다. "Primary가 갑자기 죽는" 상황을 인위적으로 만든 것이다.
시작 직전 대시보드는 모든 게 정상이었다. DB 커넥션 10개 안정, 5xx 0건, p99 10.7ms.
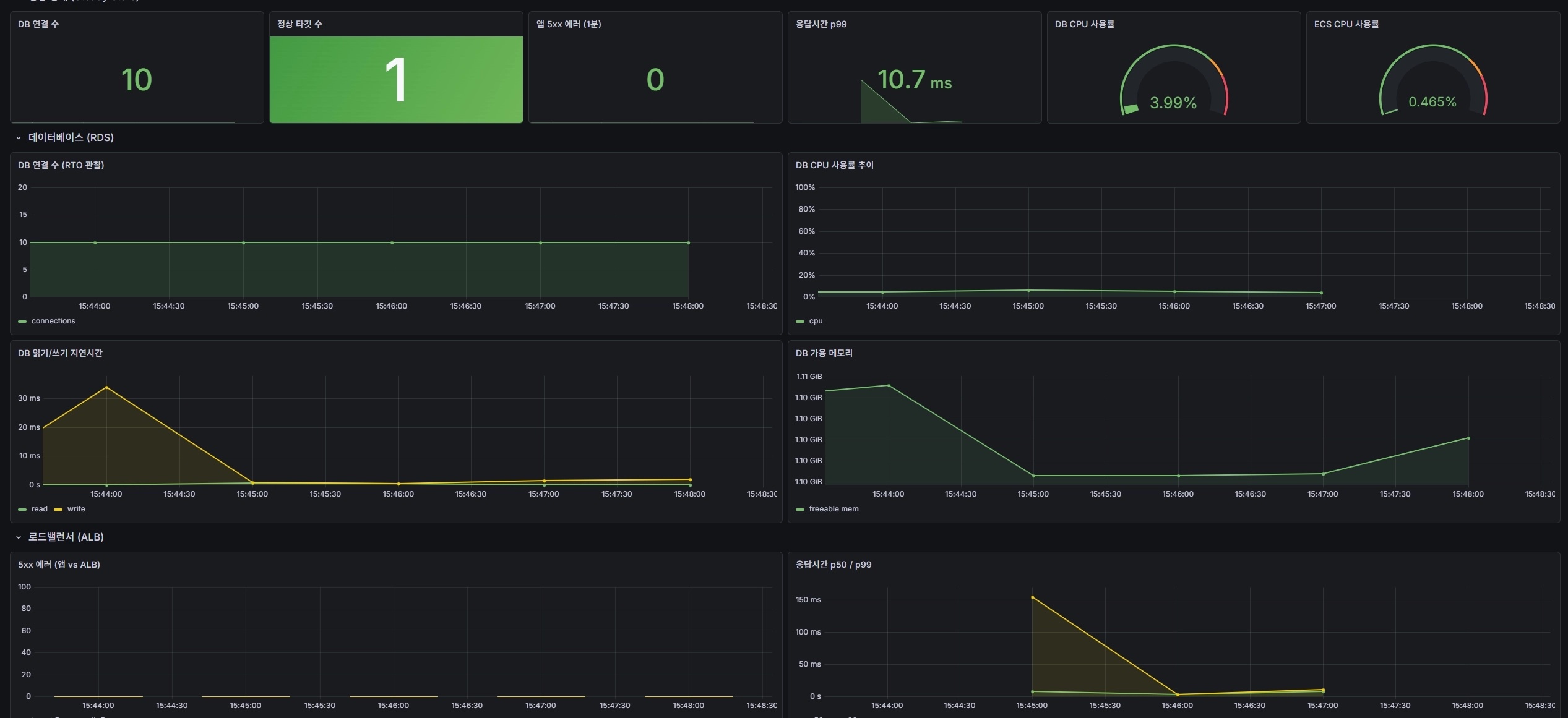
그림 1. 1차 — 시작 전 정상 기준선. DB 커넥션 10 · 정상 타깃 1 · 앱 5xx 0 · p99 10.7ms · DB CPU 3.99%. 이후 그림과 비교할 'before' 상태.
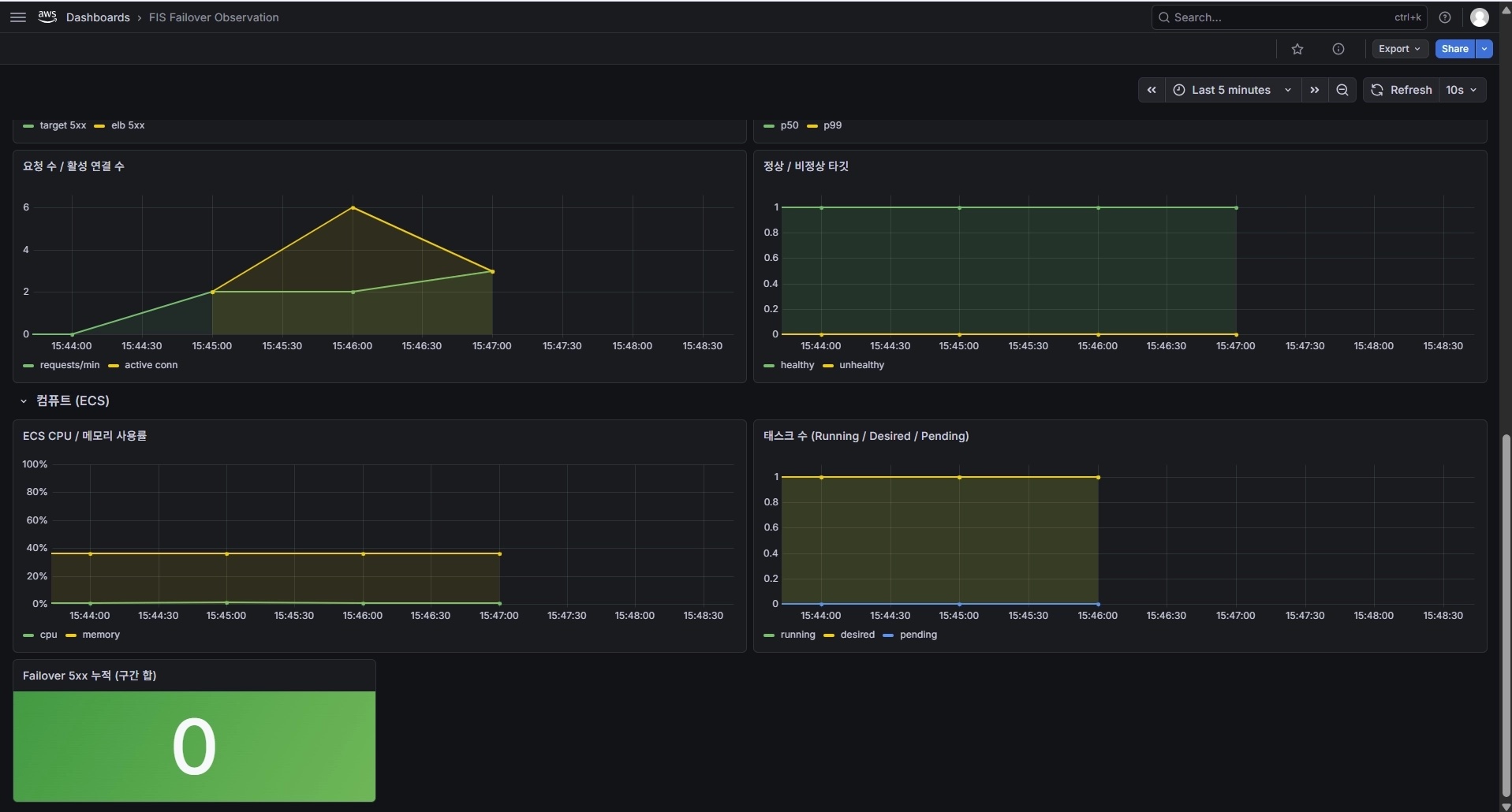
그림 2. 1차 — 장애 직전 상세. 요청 수·활성 커넥션·ECS 태스크 running 1 · Failover 5xx 누적 0. 아직 모든 지표 정상.
그런데 failover를 건 직후, 5xx가 폭증하기 시작했다.
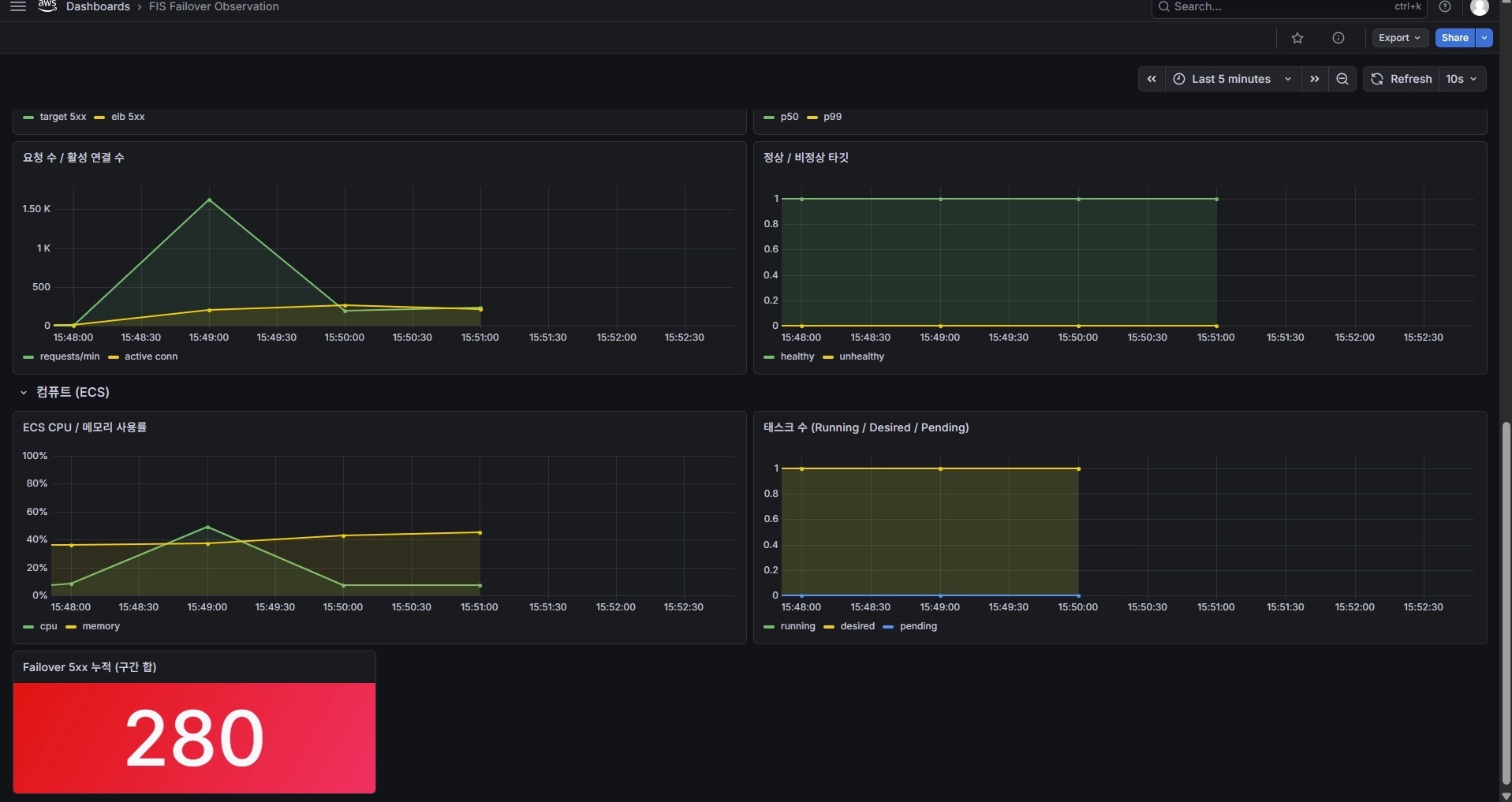
그림 3. 1차 — 장애 정점. 요청 1.5K 스파이크, Failover 5xx 누적 280건(대부분 앱 target 5xx). DB와 ECS는 멀쩡히 살아있는데(태스크 running 1) 앱이 DB에 못 붙어 5xx가 터졌다. 이 한 장이 'DB 가용 ≠ 서비스 가용'을 그대로 보여준다.
이상했다. DB CPU도, 메모리도, ECS 태스크도 전부 건강했다. 그런데 앱은 5xx를 쏟아냈다. 전환 구간을 들여다보니 DB 커넥션이 10에서 5로 빠지고 p99가 396ms까지 치솟았다.
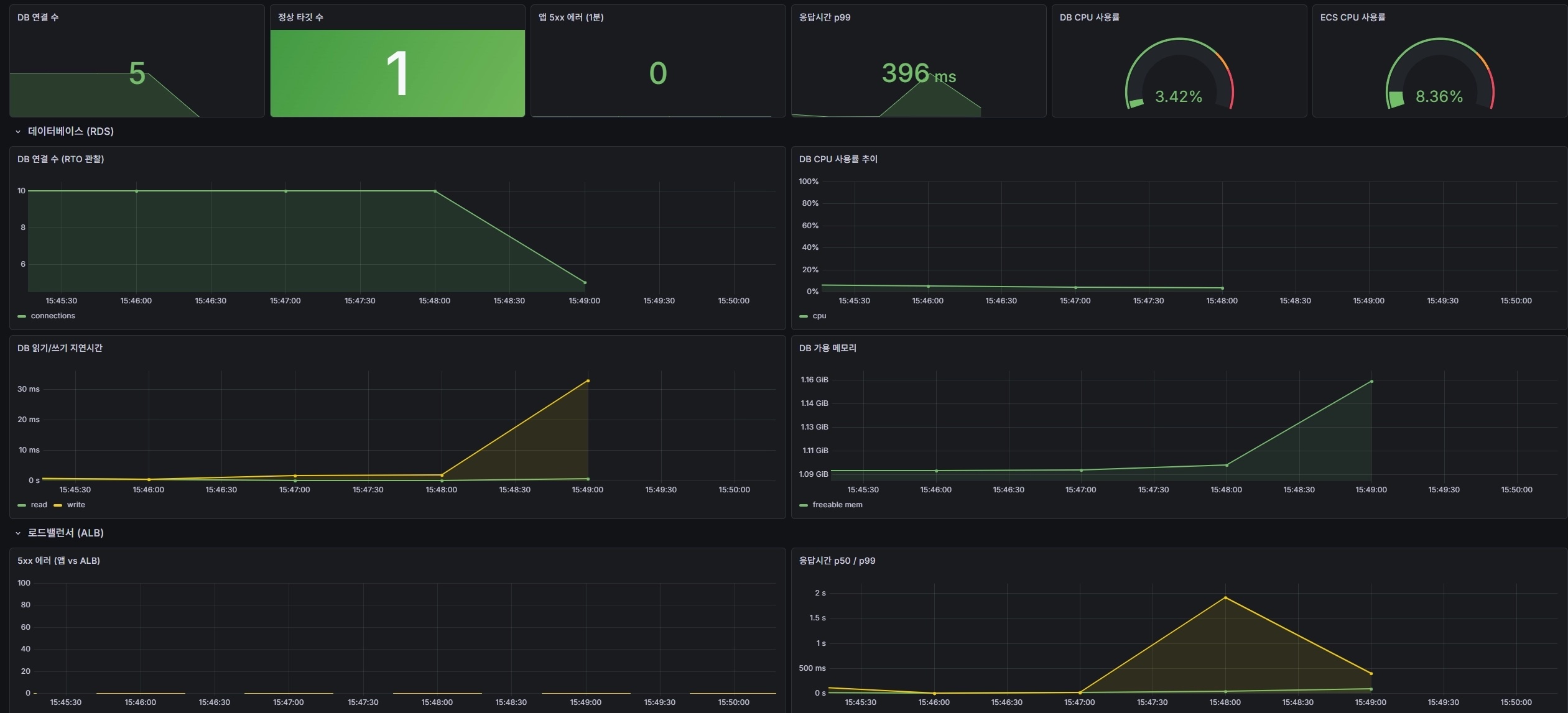
그림 4. 1차 — 전환 중. DB 커넥션 10→5 감소, 읽기/쓰기 지연 스파이크와 함께 p99가 396ms(p50/p99 패널은 2초까지)로 상승. 앱이 옛 Primary의 죽은 커넥션을 붙들고 새 Primary로 못 옮겨가는 구간.
그리고 한참 뒤에야 앱이 회복됐다.
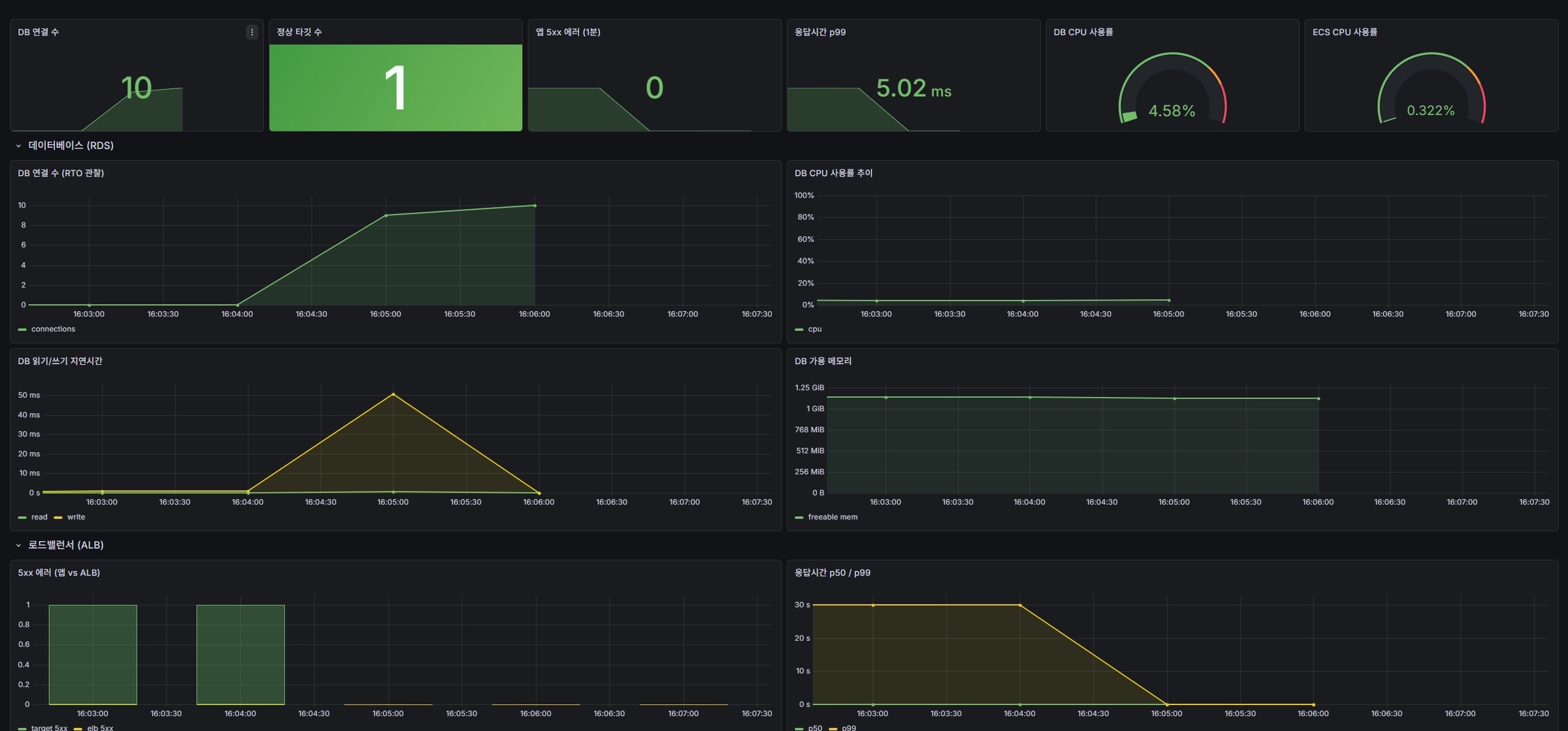
그림 5. 1차 — 종료 후 회복. DB 커넥션 0→10 복귀, p99가 30초(커넥션 대기 천장)를 찍었다가 5.02ms로 정상화. 5xx 막대는 16:03~16:04에 잡힌다. DB는 진작(15:50) 복구됐는데 앱 재연결은 16:05. 체감 RTO ≈ 15분의 끝.
정리하면 1차의 숫자는 이렇게 갈렸다.
| 지표 | 값 |
|---|---|
| DB RTO (인프라) | 약 1분 — <120초 합격 |
| 앱 체감 복구 | 약 15분 — DB는 15:50 복구, 앱 재연결은 16:05 |
| API p99 | 정상 ~10ms → peak 약 31초 → 복구 ~5ms (p50은 ~2.6ms 유지) |
| 누적 5xx | 280건 — 대부분 앱 5xx, ALB 자체는 3~6건 |
| ALB Healthy | 장애 내내 1 유지 — 헬스체크가 DB 단절을 못 봄 (맹점) |
p50은 멀쩡한데 p99만 31초로 튀었다. 이건 DB에 의존하는 요청만 막혔다는 뜻이다. 병목은 ALB가 아니라 앱↔DB 연결 구간이었다.
그리고 더 무서운 건 ALB 헬스체크가 이 단절을 전혀 못 봤다는 것이다. Healthy 타깃은 장애 내내 1로 떠 있었다. ALB 입장에선 "타깃 살아있네" 하고 죽은 경로로 계속 트래픽을 보낸 셈이다.
왜 1차가 실패했나? failover 직후 RDS가 Standby를 다시 동기화(재동기화)하는 시간을 기다리지 않고 곧바로 다시 실행했기 때문이다. 이게 2차에서 검증할 가설이 됐다.
3. 2차: 이번엔 기다렸다, 그리고 회복을 관측했다
2차는 단 하나만 바꿨다 — failover 후 RDS 동기화가 완료될 때까지 기다렸다가 다음 회차를 실행했다. 설정은 한 줄도 안 건드렸다. 그렇게 18:45 / 18:56 / 19:16, 세 번 깨끗하게 때렸다.
| 구분 | 1차 | 2차 |
|---|---|---|
| 실행 방식 | 동기화 완료 전 곧바로 재실행 | 동기화 완료까지 대기 후 실행 |
| 실행 횟수 | 2회 | 3회 |
| 결과 | 실패 — 전환 도중 앱 오류 폭증 | 정상 — 매 회차 깨끗하게 전환·관측 |
매 회차 깨끗하게 전환됐다. DB 연결 수 그래프를 보면 failover 시점에 커넥션이 잠깐 푹 꺼졌다가 다시 차오르는 게 그대로 보인다.
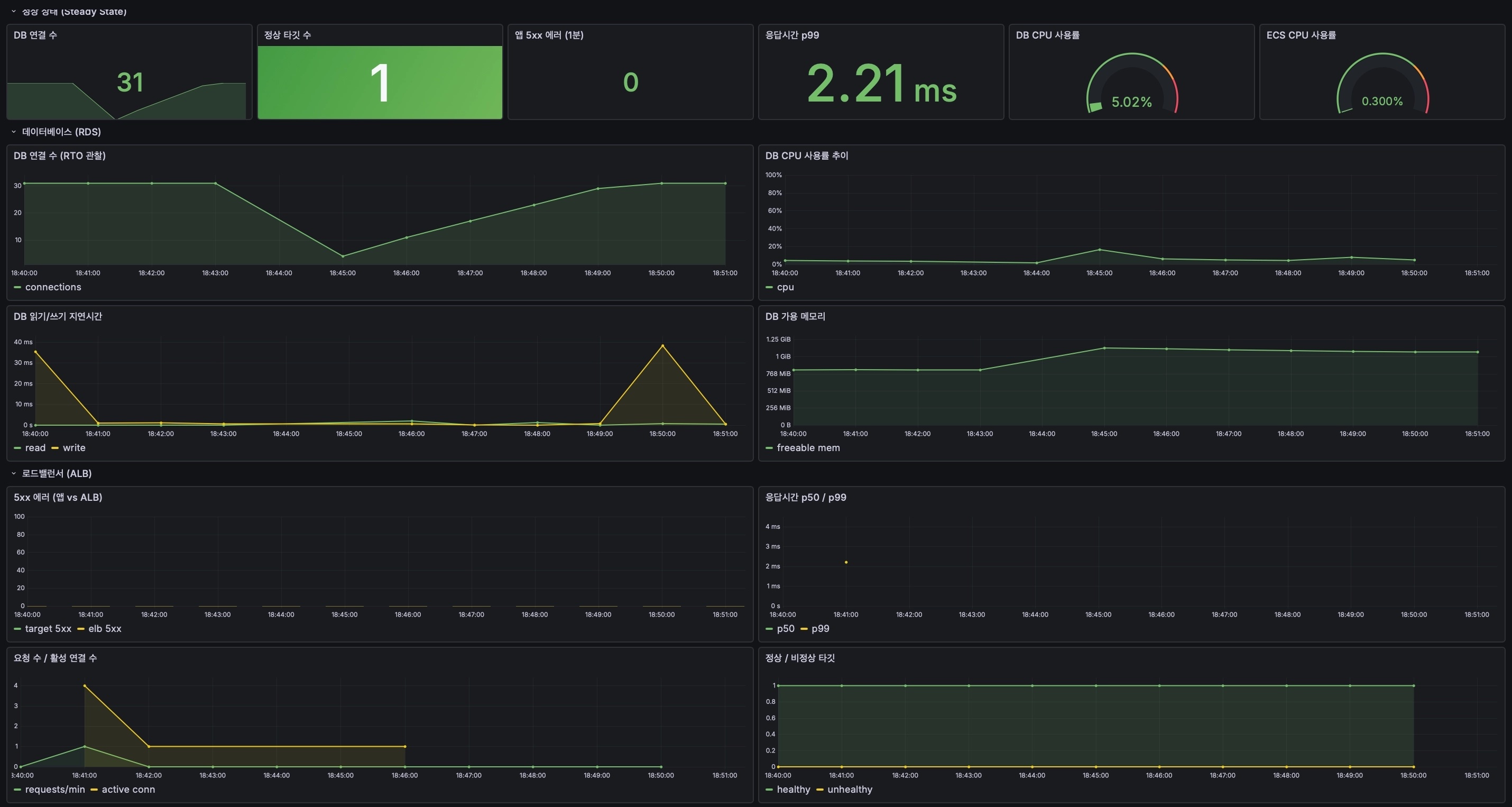
그림 6. 2차 1회차(18:45) — p99 2.21ms · DB CPU 5.02% · 정상 타깃 1. DB 연결 30 → failover 시점 일시 감소 → 30 복귀. 동기화 완료를 기다린 뒤 실행하니 깨끗이 전환됐다.
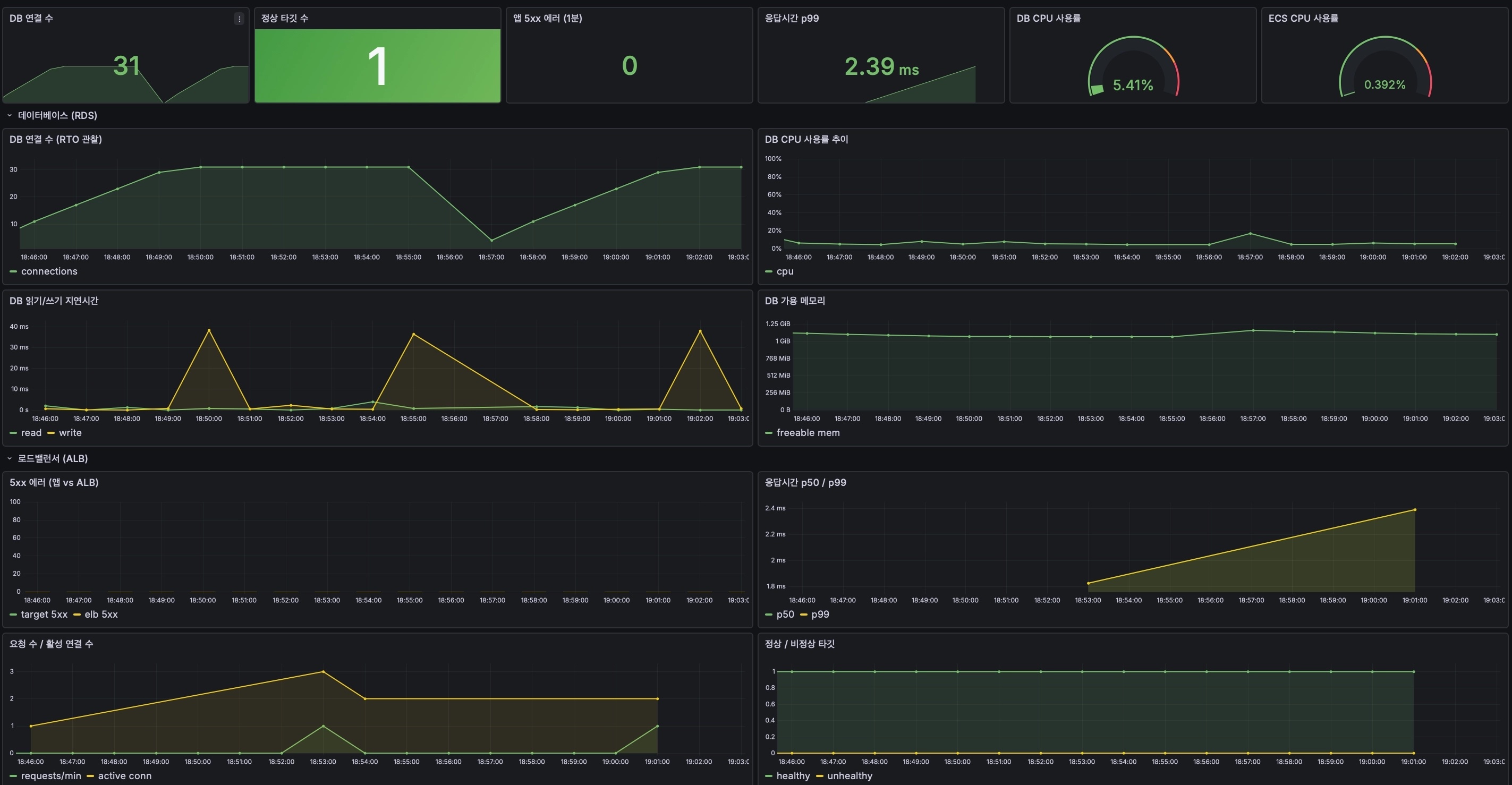
그림 7. 2차 2회차(18:56) — p99 2.39ms · DB CPU 5.41%. 같은 패턴이지만 앱 커넥션 풀 회복이 약 2분으로 빨라졌다.
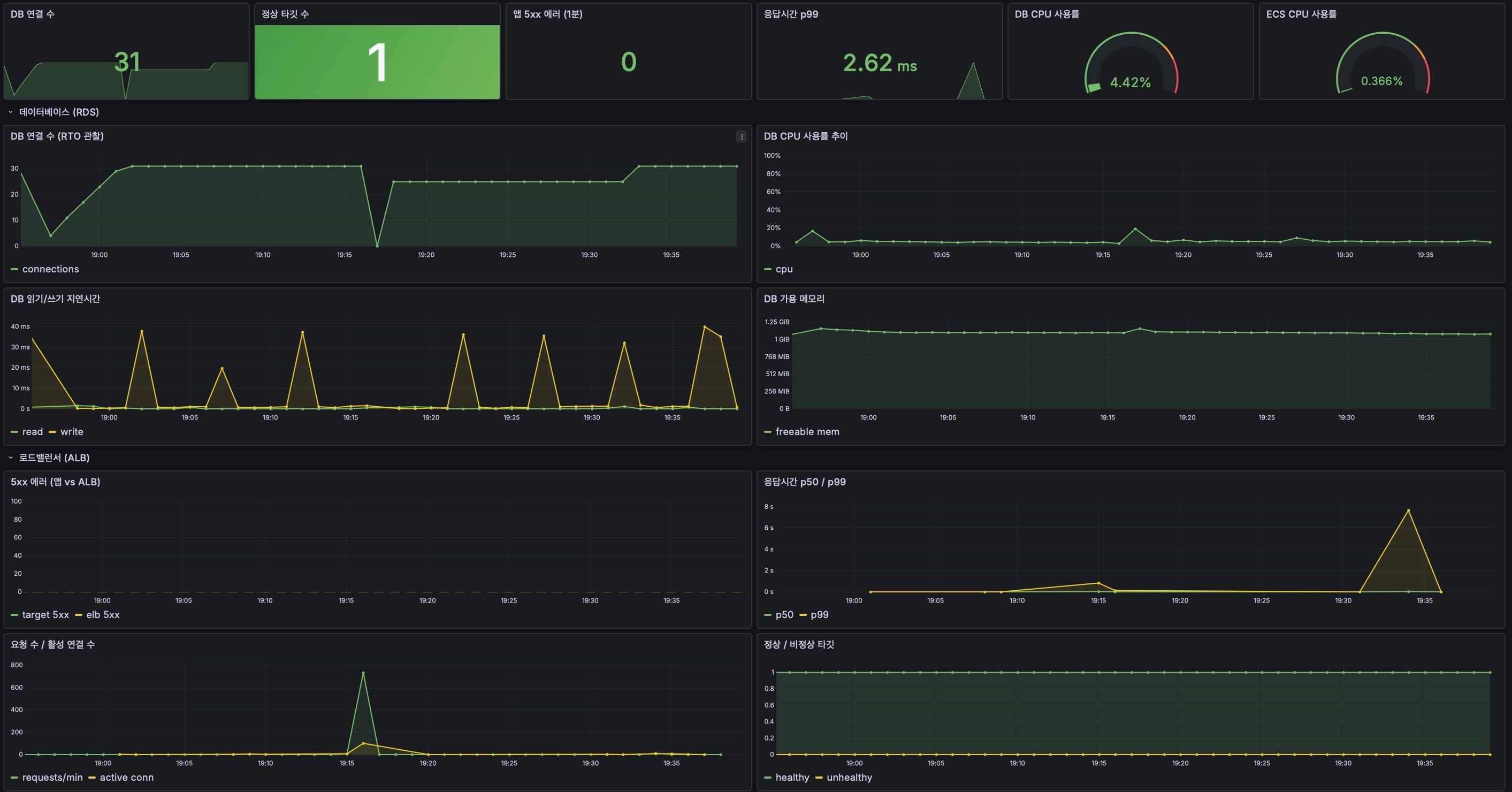
그림 8. 2차 3회차(19:16) — p99 2.62ms. 읽기/쓰기 지연 스파이크가 짧게 여러 번 났다 회복. 요청 700 스파이크도 잠깐 보인다 — 요청 스레드가 죽은 커넥션을 즉시 일괄 폐기해 앱 회복이 약 20초까지 빨라졌다.
DB 자체 복구는 RDS 이벤트 로그로 실측했다.
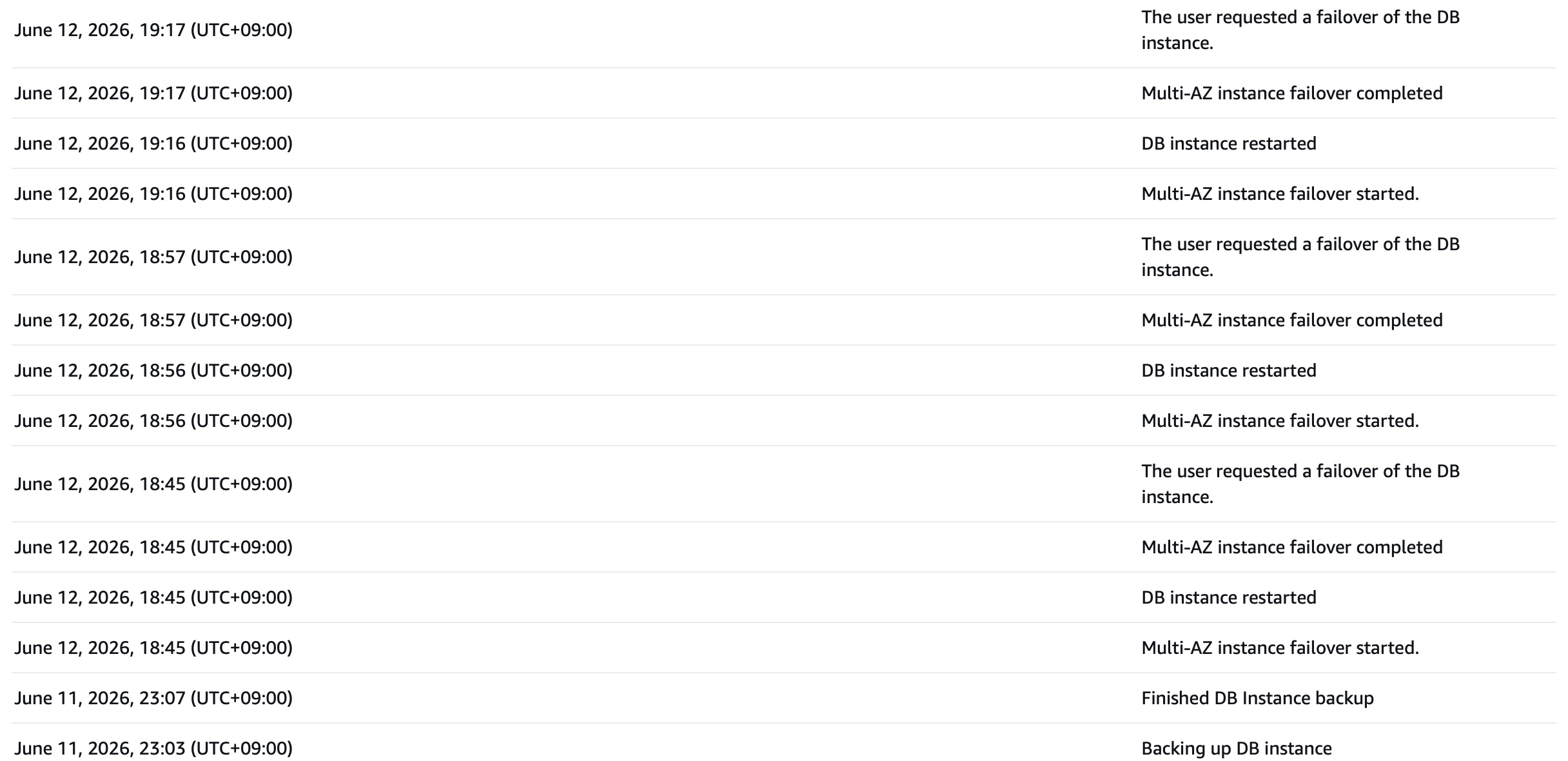
그림 9. 2차 — RDS Recent events. 18:45·18:56·19:16 세 번 모두
Multi-AZ failover started → DB instance restarted → failover completed. DB 자체 복구 15초·전체 30~45초의 실측 근거. (위 6/11 23:03·23:07은 정기 백업.)
text1[2차 — RDS Multi-AZ failover events] 21회차 18:45:02 started → 18:45:18 restarted → 18:45:31 completed (AZ 2c→2a) 32회차 18:56:17 started → 18:56:32 restarted → 18:57:01 completed (AZ 2a→2c) 43회차 19:16:27 started → 19:16:42 restarted → 19:17:01 completed (AZ 2c→2a)
3회 측정을 표로 모으면 이렇다.
| 지표 | 1회차 | 2회차 | 3회차 | 평균 |
|---|---|---|---|---|
| DB 자체 복구 | 16초 | 15초 | 15초 | 15.3초 |
| 전체 완료 | 30초 | 45초 | 35초 | 36.7초 |
| 앱 커넥션 풀 복구 | ~5분 | ~2분 | ~20초 | — |
| ECS 태스크 교체 | 없음 | 없음 | 없음 | — |
여기서 눈에 띄는 줄이 앱 커넥션 풀 복구: 5분 → 2분 → 20초다. 설정은 동일했는데 왜 점점 빨라졌을까?
4. 핵심 분석 — DB는 15초, 앱은 15분, 그 사이 14분의 사각
같은 failover 한 번을 두 계층이 전혀 다른 시간으로 겪었다. 그림으로 보면 이렇다.
text1시간축 0 15초 15분 2 │ │ │ 3DB 계층 ──────● (복구 ~15초) 4 │ 5앱 계층 ──────○━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━● 6 failover ↑ DB는 살아있으나 앱이 못 붙는 구간 ≈ 14분 ↑ 앱 복구
'가용성'을 DB 한 층으로만 재면 저 가운데 14분이 통째로 가려진다. 사용자가 실제로 겪는 시간은 가장 느린 계층, 즉 앱이 결정한다.
왜 앱이 늦게 붙었나 — HikariCP의 죽은 커넥션
failover로 Primary가 바뀌면, 풀 안의 연결들은 전부 옛 Primary를 향하는 죽은 연결이 된다. 문제는 이 죽은 연결을 언제 감지해서 새 연결로 갈아끼우느냐다.
- 1회차 (~5분) — 죽은 커넥션 감지 후, housekeeper 스레드가 10초에 1개씩 검증·폐기했다. 풀 ~20개를 다 갈아끼우는 데 5분. 로그엔 'Thread starvation or clock leap detected'가 동반됐다.
- 2회차 (~2분) — 같은 패턴이지만, 직전에 한 번 갈린 풀이라 수명 짧은 연결이 섞여 더 빨리 교체됐다.
- 3회차 (~20초) — 요청 스레드가 즉시 감지해 0.5초 안에 풀 전체를 일괄 폐기했다(housekeeper 10초 대기 없이). 단, 직후 새 연결 생성이 몰리며 'request timed out after 30000ms'가 짧게 났다 정상화됐다.
회차가 빨라진 건 '개선'이 아니다 — warm pool 함정
여기가 제일 중요하다. 5분 → 20초는 내가 뭘 고쳐서가 아니다. 한 번 failover를 겪으면 풀이 통째로 새 연결로 갈린다. 그 직후 회차는 "방금 만들어 수명이 거의 0인" 신선한 연결만 남은 상태(warm pool)가 되고, 그 덕에 우연히 빨라진 것뿐이다.
문제는 실제 운영 failover는 며칠~몇 주 멀쩡히 돌던 cold pool에서 딱 한 번 터진다는 것. 즉 현실은 늘 '1회차(5분)' 상황이지 2·3회차(빠름)가 아니다. 첫 회차가 5분이나 걸린 직접 원인은 maxLifetime 기본값이 30분이라 housekeeper가 죽은 연결을 천천히 교체했기 때문이다.
참고로 "warm pool"은 EC2 Auto Scaling의 Warm Pools와는 완전히 다른 개념이다. 여기선 "커넥션 풀이 한 번 갈려서 신선해진 상태"를 가리킨다.
5. 판정과 개선 과제
AWS 기대치 대비로 보면 인프라는 전부 통과, 앱만 숙제로 남았다.
| 지표 | 결과 | AWS 기대치 | 판정 |
|---|---|---|---|
| DB 자체 복구 | 15~16초 | 30초 이내 | 양호 |
| 전체 Failover 완료 | 30~45초 | 60초 이내 | 양호 |
| 데이터 손실 | 없음 (동기복제) | 무손실 | 양호 |
| ECS 태스크 생존 | 전 회차 교체 없음 | — | 양호 |
| 앱 에러 구간 | 최대 ~5분 · 체감 ~15분(1차) | — | 개선 필요 |
개선 1순위는 HikariCP 튜닝이다.
| # | 조치 | 기대 효과 |
|---|---|---|
| 1 | max-lifetime = 60000 (60초) | 커넥션 수명 단축 → failover 시 빠른 교체 |
| 2 | connection-timeout = 5000 (5초) | 새 연결 실패 시 빠른 에러 반환 |
| 3 | keepalive-time = 30000 (30초) | 주기적 alive 체크 → 죽은 연결 조기 발견 |
| 4 | validation-timeout = 3000 (3초) | validate 빠른 실패 처리 |
| 5 | ECS min 태스크 2개 이상 | 1개가 죽어도 다른 태스크가 커버 |
그 외에 1차에서 도출한 개선들:
- Deep health check — ALB 헬스체크가 DB 연결까지 점검하게. Healthy=1 맹점을 없애 죽은 경로로 트래픽 보내는 걸 차단.
- 알람 기준 보강 — Healthy 수가 아니라 5xx·DB 활성 커넥션 수 기준으로.
- FIS 템플릿에
aws:fis:wait추가 — reboot는 13초 fire-and-exit라 정작 장애 구간엔 실험이 끝나 Stop Condition이 무력화된다. wait로 실험 수명을 복구 구간까지 늘려야 한다.
마치며
이 실험의 목적은 "Multi-AZ가 장애를 견디는가"를 추측이 아니라 숫자로 확인하는 것이었고, 결과는 두 계층으로 뚜렷이 갈렸다.
- 검증된 것 — Multi-AZ failover 메커니즘 자체는 정상이다. DB 복구 15~16초, 데이터 무손실, AZ 자동 전환, ECS 태스크 생존. 인프라 회복력은 합격.
- 발견한 것 — 서비스 RTO를 좌우하는 건 DB가 아니라 앱이었다. HikariCP가 죽은 연결을 늦게 교체해 1차 체감 복구가 ~15분, 5xx 280건. 그 와중에 ALB 헬스체크는 DB 단절을 못 봤다.
- 운영 교훈 — failover 직후 RDS 재동기화가 끝나기 전에 재실행하면 안 된다(1차 실패 원인). 그리고 풀 회복이 빨라 보인 건 warm pool 효과일 뿐, 실제 운영은 늘 '5분' 상황이라 튜닝이 전제다.
가장 크게 남은 한 줄은 이거다.
서비스 가용성은 가장 빠른 계층이 아니라 가장 느린 계층이 결정한다. DB가 15초 만에 살아나도 앱이 14분을 못 붙으면, 사용자에게 그 서비스는 14분간 죽어 있던 것이다. 'Multi-AZ를 켜 두는 것'과 '장애를 실제로 견디는 것'의 차이가 바로 여기에 있다.
이게 카오스 엔지니어링을 직접 해보기 전엔 안 보이던 사각지대였다. 체크박스를 켜는 것과, 깨뜨려서 숫자를 보는 것은 정말로 달랐다.
Further Reading
Newer
–댓글 0개
첫 번째 댓글을 남겨보세요